An alternative for classical machine learning? A closer look at SAP’s RPT-1
Architecture
RPT-1, which stands for Relational Pretrained Transformer (obviously a nod to the one of the world’s most revolutionary AI models) is a rebrand of the ConTextTab model built by a team of SAP’s in-house scientists which was released earlier in 2025.
The main idea from the paper linked above is that RPT-1 is trained on tabular data usually found in enterprise database systems, in contrast to LLMs which are text-based and meant to continue a given sequence of text tokens. An important difference in its architecture is that the attention mechanism that computes the importance of words in a sentence against each other in a regular LLM now works in two dimensions, meaning that both cross-column and cross-row attention are calculated for each cell. This means that the model takes into account the relationship of the cells within each single row, but also of the cells in each column, providing a 2D approach of continuing a sequence. This contrasts with the GPT-models which continue a sequence of words along a single dimension only.
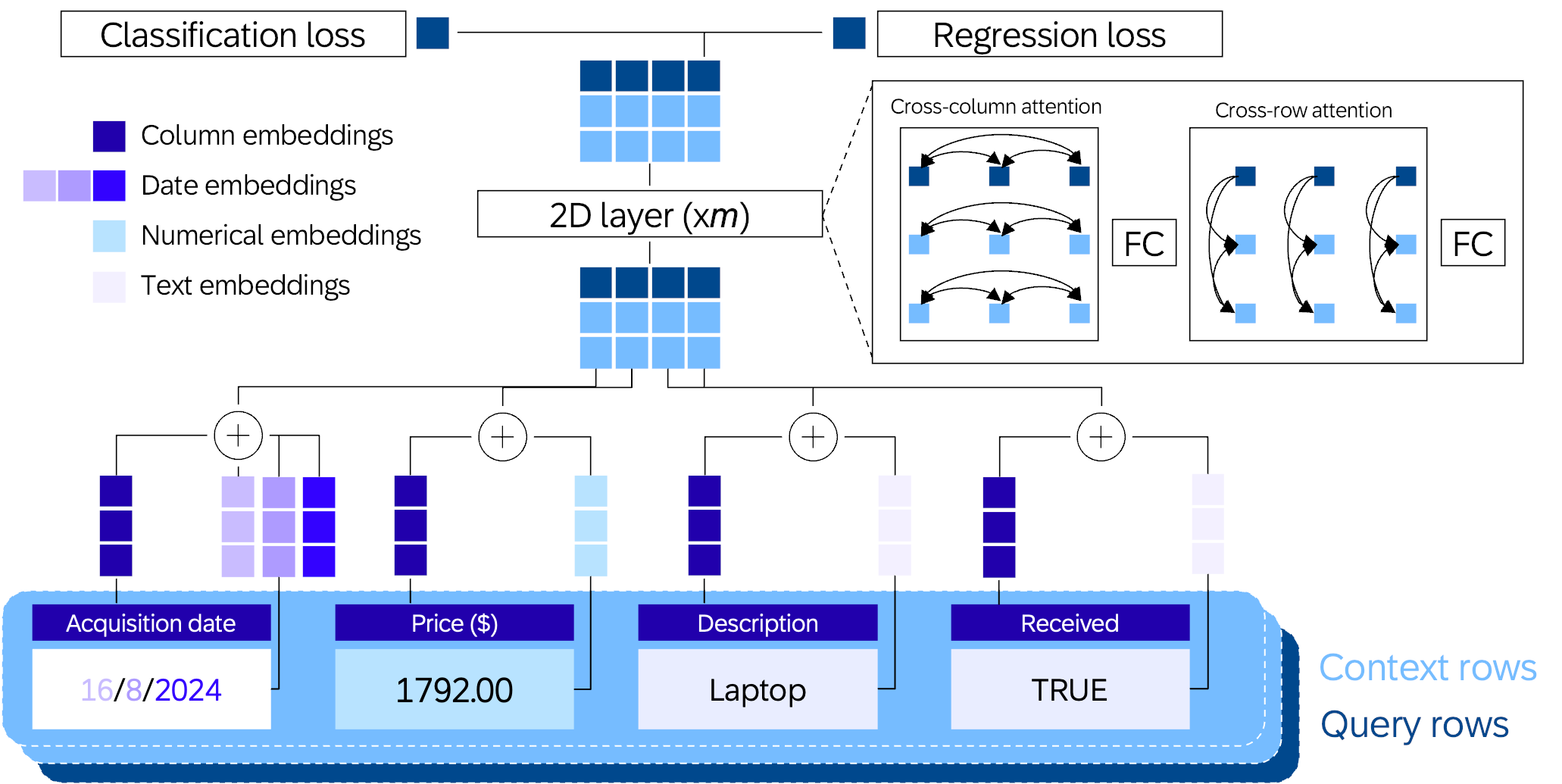 Figure 1 - RPT-1 architecture
Figure 1 - RPT-1 architecture
Another improvement has to do with the way that tabular data is usually strictly typed in databases: RPT-1 model uses different types of embeddings for different types of data, allowing for richer information to be captured depending on the type of its column.
In practice, these improvements allow the model to continue a series of numerical values stored in a column where each row is a timestamp (necessary for time series forecasting). It is also able to fill in blank cells based on the values in surrounding columns, which can also be regarded as a classification scenario.
The model has been pretrained on the T4 dataset, which amounts to 1.3 TB of tabular data.
Use cases
It is important to distinguish RPT-1 from the many LLMs you see being embedded into all kinds of tools around you nowadays. Where an LLM is intended to continue a text sequence, RPT-1 is meant to continue values in tables or fill in blanks and is exclusively meant to work with tabular data. It therefore lives in an area which was previously dominated by algorithms which are nowadays seen as classical machine learning. Predictive analysis methods falling under this category are classification, regression or time series forecasting. These algorithms are nevertheless still very popular nowadays, with gradient boosted trees being a popular choice for year for both classification and regression problems.
An important distinction is that these classical machine learning algorithms all require training on your domain-specific dataset before they can be used. RPT-1 had been pretrained on such a large body of tabular data that its promise is to be able to execute these machine learning tasks in a one-shot fashion without specific post-training on your domain data, just like you would be doing with an LLM.
Just like with LLMs, RPT-1 works by distilling patterns and creating intermediate features using the large numbers of parameters that its underlying neural network provides.
RPT-1 Playground
SAP has released two different approaches of working with RPT-1 yourself. The most straightforward way is by using the RPT-1 Playground, which presents you with a graphical frontend to load in your own dataset and set up some predictions yourself. There are also a few sample datasets included in the tool to get started even faster.
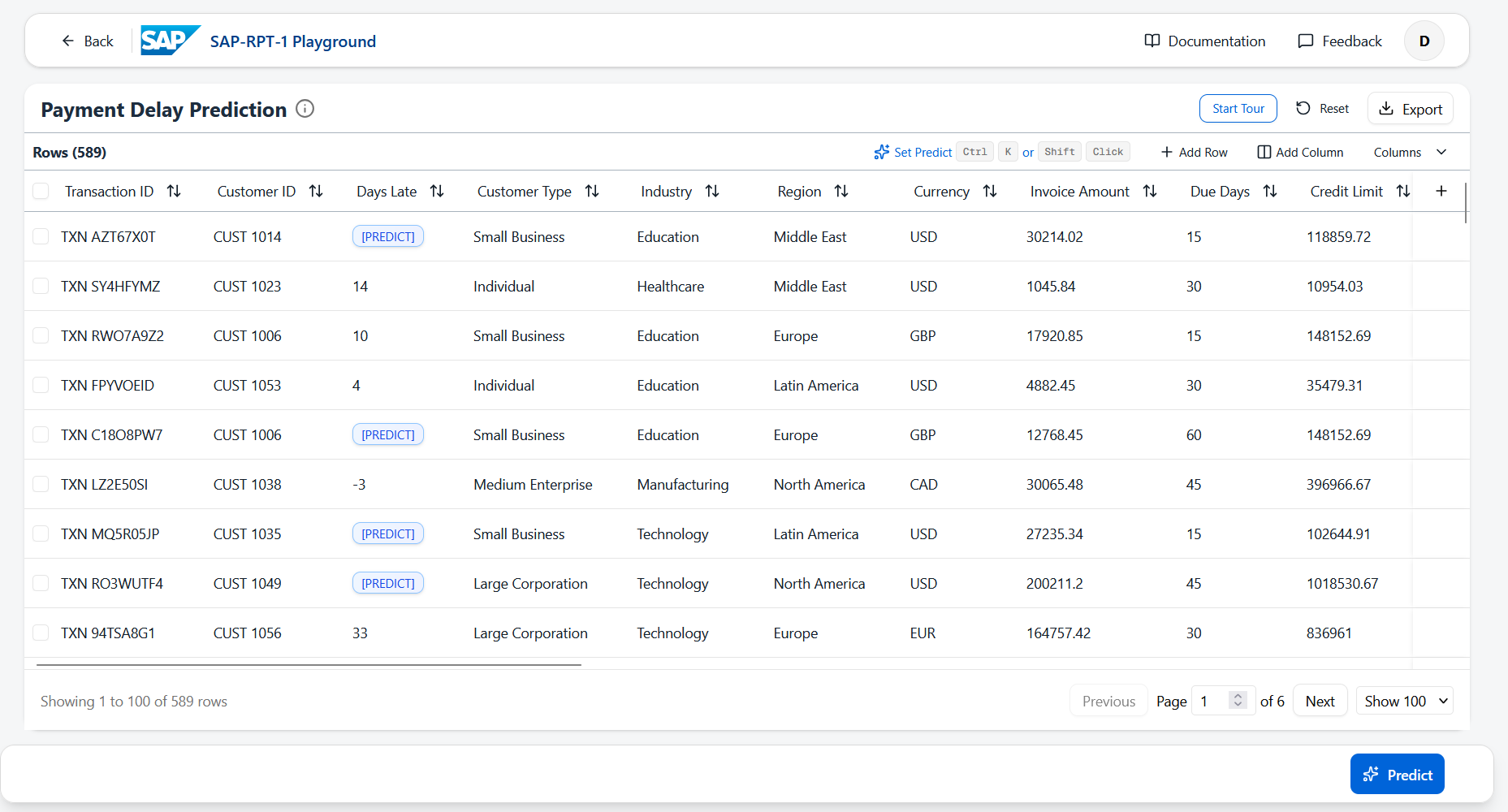 Figure 2 - RPT-2 playground
Figure 2 - RPT-2 playground
In practice, although the playground offers a quick and easy way to test out RPT-1 functionality tailored towards business users, I feel this is mainly intended to be used as a tech demo as your data scientists or machine learning engineers require a way to embed this into their transformation pipelines using code. I will therefore explore two other deployment options in the next part, being the OSS and commercial versions.
RPT-1 OSS version
A second option to test and deploy RPT-1 is the one I will be investigating a bit more. This is based on an OSS version of RPT-1 which can be downloaded from Huggingface at https://huggingface.co/SAP/sap-rpt-1-oss. This marks a significant step from SAP towards more openness of their development stack and catering to developers from other ecosystems as well.
The OSS model is most probably a toned-down version of the two commercially available models, meaning that it may have a smaller parameter count and therefore be less accurate, although SAP does not disclose parameter counts for any of the RPT-1 models. It does allow you to run it on a hyperscaler of your choice or even on-premise. Although the model card on Huggingface recommends at least 80 GB of VRAM, the model ran perfectly fine on an older NVIDIA T4 with 16 GB VRAM and even an RTX with 12 GB.
Installation instructions
My testing notebook is located at the following GitHub repo: https://github.com/kemperd/rpt-1-demo
The results are immediately visible in the notebook itself, but if you like to run it make sure to create a Python (3.11.14) virtual environment first and install dependencies using:
pip -r requirements.txt
Testing
I will be conducting both a classification and regression test on a few toy datasets from Scikit-learn: for the classification problem I will use the breast cancer and wine datasets and the regression problem will be with two housing prices datasets from Boston and California.
For both types of prediction problems, I will be comparing a set of algorithms with a few default parameter settings that will not be changed during the test. This will not resemble real-world testing at all (you most probably want to test optimal hyperparameters settings too), but it at least allows us to see where RPT-1 stacks up against a few of the most-used classical machine learning algorithms.
The results of the classification problems are shown below:
| Breast cancer | Wine | |
|---|---|---|
| Nearest Neighbors | 0.957895 | 0.932584 |
| Linear SVM | 0.985965 | 0.966292 |
| RBF SVM | 0.656140 | 0.382022 |
| Gaussian Process | 0.968421 | 0.606742 |
| Decision Tree | 0.940351 | 0.910112 |
| Random Forest | 0.940351 | 0.955056 |
| Neural Net | 0.982456 | 0.988764 |
| AdaBoost | 0.968421 | 0.921348 |
| Naive Bayes | 0.940351 | 0.988764 |
| QDA | 0.961404 | 0.932584 |
| RPT-1 | 0.978947 | 0.988764 |
Table 1 - Classification acccuracy
As you can see, RPT-1 ranks with the best algorithms for the wine classification problem and it is top-3 in the breast cancer case. All results are pretty close and there doesn’t really seem to be a badly performing algorithm for both of these problems.
The regression results are as follows:
| Boston housing | California housing | |
|---|---|---|
| Linear | 0.689291 | 0.599482 |
| Huber | 0.664190 | 0.585378 |
| Linear SVM | 0.658854 | 0.578598 |
| RBF SVM | 0.586780 | 0.724145 |
| Decision Tree | 0.650036 | 0.563894 |
| RPT-1 | 0.891789 | 0.868549 |
Table 2 – Regression accuracy (R2 score - higher is better)
Here you can really see where RPT-1 shines, scoring significantly better than the next-best algorithms. This shows you definitely should consider adding RPT-1 to your list of algorithms when doing an initial comparison of algorithms when tackling a new use case.
Commercial versions
A third and last option for deploying RPT-1 is making use of a commercially available (closed-weight) RPT-1 models. SAP offer two versions of the commercial models (sap-rpt-1-large and sap-rpt-1-small). The large version of the commercial model is intended to be the stronger (more accurate) version while the small version is meant to be faster. These models are intended to be run on SAP AI core, which SAP calls its “AI operating system”. In practice, SAP AI core delivers the technical framework and underpinnings for running large neural-network based models on cloud infrastructure, allowing the models to run on GPUs. For deployment of the models and managing their lifecycle SAP offers the AI Launchpad, which acts as a GUI on top of AI Core. Developers will be interacting with the models through API calls that the AI Core platform exposes.
I expect the commercial versions to perform even better than the OSS version. These will be a good option for customers already running SAP AI Core without the added complexity of deploying and running a large transformer-based model on own infrastructure.
Wrapup
As the above demo has shown, RPT-1 is an interesting alternative to classical machine learning methods and shows that pretrained models should definitely be considered when selecting an algorithm for classification or regression problems. Regression problems are especially well-suited for RPT-1. Even though SAP stated much higher system requirements, the open-source version of RPT-1 can be loaded in modest on-premise hardware.
Dirk Kemper
sap rpt-1