
AI-powered website scraping and content analysis
I decided to try and tackle this problem using a Semantic Search architecture pattern, which is a form of RAG. As the AI engineering field is evolving in such a fast pace and is changing under your eyes daily, the current hype is to build everything in the form of agentic AI. Some may argue that this RAG pattern is therefore a bit outdated, even though it is just a few years since its initial conception. However, I feel there are good reasons to rightsize your solution and not always use agents as your go-to architecture, which I will go into at the end of this blog post.
Code
The code of the Streamlit-based tool is available at https://github.com/kemperd/ai-scraper, including instructions on how to install it.
Architecture
The full architecture of the solution is given below:

This diagram displays the following flow of information:
- A company website is extracted by using a simple custom-made website crawler, simply following and indexing all links from a specified domain
- All links are converted into digestible text, also when pointing to PDF and Word-files. This text is in turn sent to OpenAI’s text-embedding-3-small model to convert the document contents to proper embeddings to be used by the similarity search algorithm in the vector database
- The retrieved embeddings are stored in a Qdrant vector database, together with some metadata like document title and URL
- A prompt is constructed for an LLM which asks about the existence of specific information on a certain topic, to be found in one of 5 similar documents as retrieved from Qdrant
Scraper
There are different API-based cloud tools on the market that promise to solve the problem of scraping a full website and presenting its contents in a digestible form (e.g. JSON), to be used in LLM prompting. However, after experimenting with some of these and not being really impressed about their results, I decided to build a very straightforward site scraper based on BeautifulSoup, just indexing and retrieving all links of a specific domain.
The code for the scraper is as follows:
class Crawler:
def __init__(self, company=''):
self.visited_urls = []
self.urls_to_visit = [COMPANIES[company]]
self.company = company
self.domain = urlparse(COMPANIES[company]).netloc
self.pages = []
def download_url(self, url, content_type):
if content_type is not None:
if content_type.startswith('text/html'):
return requests.get(url).text
else:
return requests.get(url).content
def get_linked_urls(self, url, html):
soup = BeautifulSoup(str(html), 'html.parser')
for link in soup.find_all('a'):
path = link.get('href')
if path and path.startswith('/'):
path = urljoin(url, path)
yield path
def add_url_to_visit(self, url):
if url not in self.visited_urls and url not in self.urls_to_visit:
self.urls_to_visit.append(url)
def crawl(self, url):
logging.info(f'Crawling: {url}')
content_type = requests.head(url).headers.get('content-type')
body = self.download_url(url, content_type)
self.pages.append(url)
for url in self.get_linked_urls(url, body):
url_domain = urlparse(url).netloc
# Only add URLs in site domain
if url is not None:
if ( url_domain == self.domain or 'website-files.com' in url_domain ) and 'mailto' not in url:
self.add_url_to_visit(url)
def get_pages(self):
return self.pages
def run(self):
while self.urls_to_visit:
url = self.urls_to_visit.pop(0)
try:
self.crawl(url)
except Exception:
logging.exception(f'Failed to crawl: {url}')
finally:
self.visited_urls.append(url)The crawler starts from a base URL and recursively follows all A-tags to add all links to a list. After finishing, the get_pages() method is called to retrieve the full list.
Processing website content
The next step is to preprocess the site’s contents to extract all text from it. As the sites I was crawling had lots of content hidden in PDFs (even PDFs only containing scanned images), it was crucial to have a solution for those types of documents as well, apart from just processing the HTML. The Unstructured package promises to solve exactly this and is able to process data inside PDFs, HTML-files and Word documents all from a single package.
Using the Unstructured package for delivering all information as LangChain Documents is easy using its specific document loader from the LangChain’s large collection at https://python.langchain.com/docs/integrations/document_loaders/
Now before loading all documents into the vector database, I will be creating chunks of the documents so we don’t have to insert each full document into the LLM prompt when asking questions about it. I have selected a chunk size of 1000 and an overlap of 200 tokens. This means that each chunk is 1000 tokens large, while there is a 200 token overlap with the previous chunk. These settings are somewhat arbitrary and there doesn’t really seem to be a good rule of thumb here. Also, with the ever-increasing context sizes of modern LLMs, a 1000-token chunk size may be a bit limiting. Please keep in mind to experiment with other settings after you have finished implementing and not to leave this as is.
The code for loading the content is as follows:
loader = UnstructuredURLLoader(urls=crawler.get_pages())
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(documents)Storing embeddings into the vector database
Creating embeddings is straightforward by calling the appropriate OpenAI API.
embeddings = OpenAIEmbeddings()I will be using the cloud-hosted Qdrant database as a vector store [https://qdrant.tech/], which has a free tier option available for small projects like these. After creating an account you will receive the URL of your database API endpoint and its corresponding API key.
Set up a connection to Qdrant:
client = QdrantClient(
url=os.getenv('QDRANT_URL'),
api_key=os.getenv('QDRANT_API_KEY')
)I will be using a collection for each specific website, which makes it straightforward to separate their contents and perform queries for specific sites.
client.create_collection(
collection_name = company,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
qdrant = QdrantVectorStore(
client=client,
collection_name=company,
embedding=embeddings,
retrieval_mode=RetrievalMode.DENSE,
)
qdrant.add_documents(documents=all_splits)Prompting the LLM
To ask the LLM about whether specific documents are existing on the web page, I will construct a prompt combining the results from the vector database with proper instructions on how to search. The vector database will return 5 document chunks that are similar to the prompt, that need to be inserted at the correct location in the prompt
MODEL_NAME = 'gpt-4.1-mini'
llm = init_chat_model(MODEL_NAME, model_provider="openai")
# Define state for application
class State(TypedDict):
question: str
context: List[Document]
answer: str
# Define application steps
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"], k=5)
return {"context": retrieved_docs}
def generate(state: State):
docs_content = '\n\n'
for doc in state['context']:
docs_content += 'Source: ' + str(doc.metadata['source'] + '\n')
docs_content += 'Contents: ' + doc.page_content + '\n'
logging.info(docs_content)
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
template = """Use the following context to answer the question.
If you do not know the answer, just respond that you don’t know and and do not try to make up an answer.
If a document is given in the context, fully use this to answer the question.
Also provide the title and if known the file name of the document where you found the answer.
If there are headers in the text which can be used to answer Yes or No, use these as well.
Start your answer with “Yes” or “No” and the summary of what you have found.
{context}
Question: {question}
Helpful answer:"""
prompt = PromptTemplate.from_template(template)
# Compile application and test
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()Results
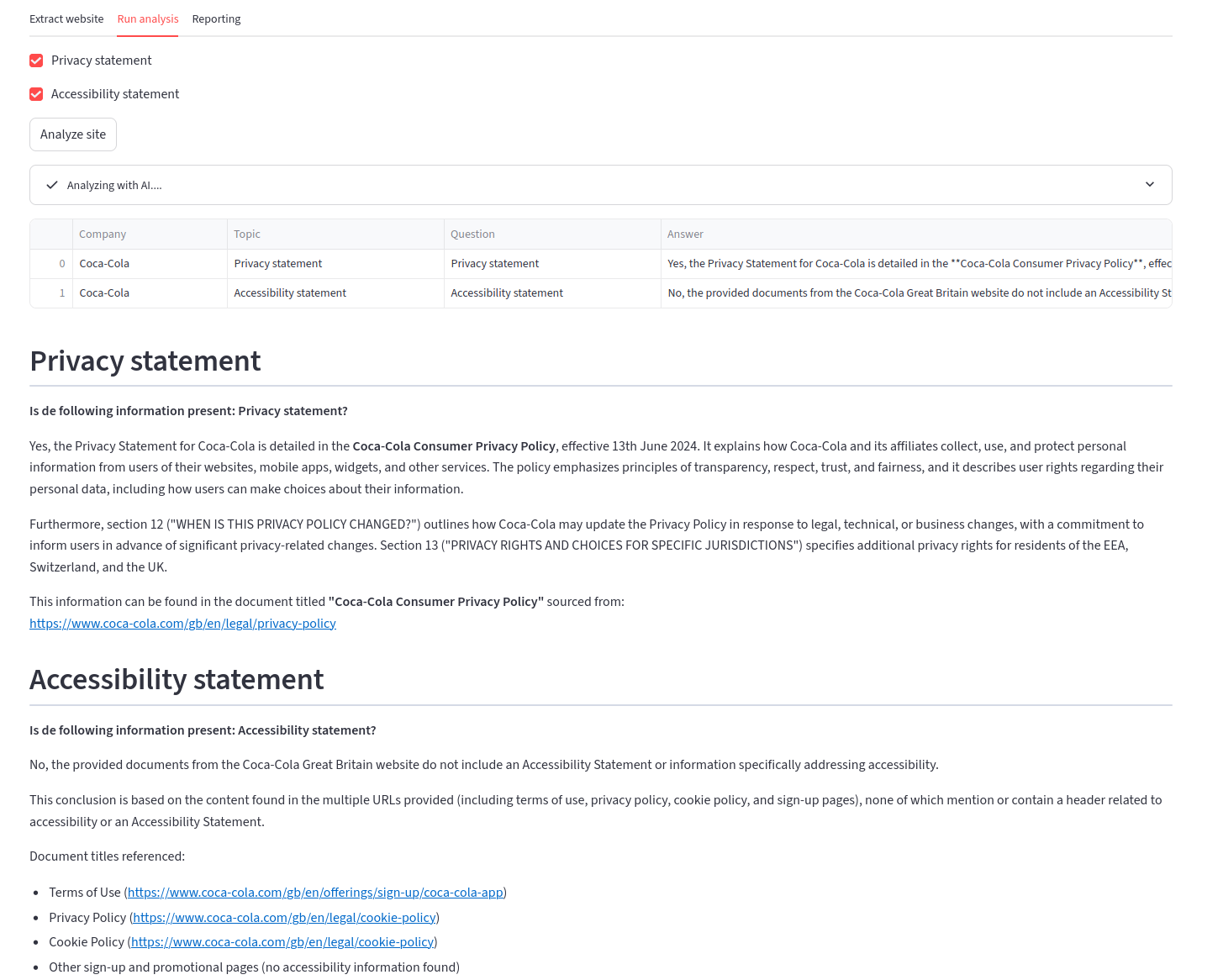
Now let’s try to use this approach to search for some specific information. Let’s say we are interested in checking if a certain site has both a privacy statement and an accessibility statement available. I will be using the corporate sites of both Coca-Cola and Unilever for this purpose. Especially the latter has a lot of annual reports in PDF-form hidden in its archive section, making it an ideal candidate to see if the solution is able to scale to Fortune 500-level corporate sites.
Extracting the Coca-Cola website took about 10-15 minutes, while the Unilever took several hours to extract and process.
The results of the questions are as follows:
Coca-Cola:
Unilever:

As you can see, the AI does a great job of identifying whether the requested documents are available on the site, including providing links of the sources.
Do we need agents for everything?
Like stated in this post’s introduction, with the current advent of agentic AI it would be an obvious choice to look into developing an agent-based solution as well. This might look as an agent that starts its crawl at the at the site’s entry point, digests each page one at a time and decides for each link that it encounters if it is worthwhile to visit that link too in order to ingest more information. Due to the fairly straightforward “search a document in a large pile of data”-nature of the use case, I used a RAG approach as this is a tried and tested architecture pattern.
To add a bit of structure to the decision of whether or not to use an agent for your use case, I would recommend to have a look at Tobias Zwingmann’s Integration-Automation AI framework.

The image of the diagram is property of Tobias Zwingmann.
Tobias outlines 4 categories in which an AI use case may fall, with assistants (like ChatGPT) having the lowest level of automation and integration, as these are not autonomically performing any tasks and also don’t integrate with your IT landscape: you need to copy and paste all information in and out of ChatGPT yourself. The web scraping use case from this blog post ends up in the Autopilot category: it is automatic in the sense that it scrapes its target sites, but there is no integration in any business processes as the outcomes manually need to be followed up by a human in the loop.
Another recommendation from Tobias’s post is to not to move to agents immediately for new use cases, but upgrading your developments either vertically or horizontally along either the integration- or automation-dimension in a single increment, not diagonally from an assistant to an agent. This further corroborates my initial architecture of not starting with an agent first, although it does indicate that the next iteration of the tool should move in the agentic direction.
Wrapup
In this blog post I have shown you an architecture and setup to successfully apply LLMs to query and analyze websites for the existence of specific information, which also may be hidden in large PDF documents. By applying this approach to the sites of two Fortune 500 companies, I have shown that the solution is scalable and works with larger sites as well. By applying proper prompting strategies we are able to have the LLM recite its sources as well.
While agentic AI is one of the most important AI development themes nowadays, you should take care in not jumping to an agentic AI for your use case and gradually build up your increment along the dimensions of integration and automation.
Dirk Kemper
qdrant gpt-4 rag langchain