 The AI field is advancing in an incredible pace and 2022 has been shaken up by a few major announcements of algorithms able to generate fantastic images just by providing a text prompt. Some incredible work has been done by the OpenAI team which introduced DALL-E 2 to the public in March 2022, but also by Google Research who introduced Imagen a few months later.
Read More ›
The AI field is advancing in an incredible pace and 2022 has been shaken up by a few major announcements of algorithms able to generate fantastic images just by providing a text prompt. Some incredible work has been done by the OpenAI team which introduced DALL-E 2 to the public in March 2022, but also by Google Research who introduced Imagen a few months later.
Read More ›
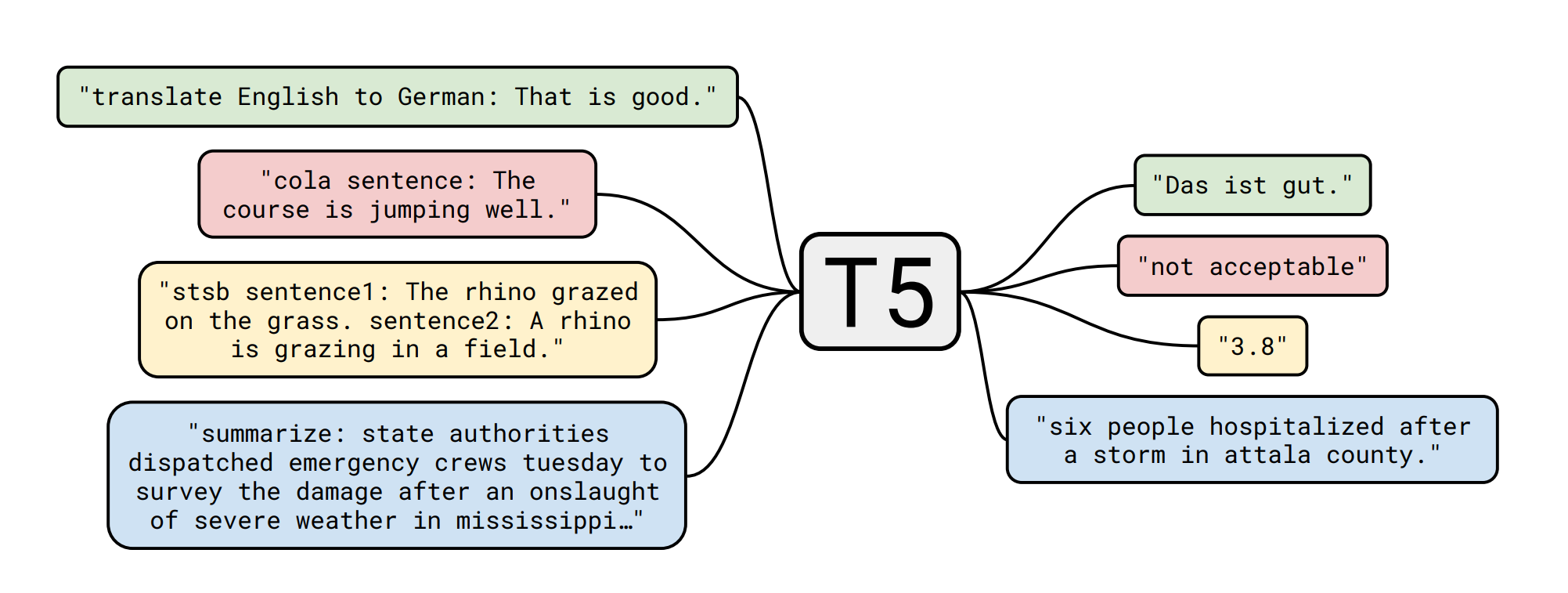 Master data maintenance is a time-consuming activity for many businesses. Companies like retailers selling large amounts of different articles or manufacturing companies processing raw materials into finished goods can easily collect databases containing hundreds of thousands of master data items, which in turn may possess many hundreds of attributes. This blog post proposes a way of populating these attributes by applying a transformer-based Large Language Model.
Read More ›
Master data maintenance is a time-consuming activity for many businesses. Companies like retailers selling large amounts of different articles or manufacturing companies processing raw materials into finished goods can easily collect databases containing hundreds of thousands of master data items, which in turn may possess many hundreds of attributes. This blog post proposes a way of populating these attributes by applying a transformer-based Large Language Model.
Read More ›
 In my previous blog post on reinforcement learning I demonstrated a way to get a gentle introduction into this field by using Keras-RL2. While writing that I found it quite difficult to get an overview of the many reinforcement learning frameworks available today which all have different levels of maturity. In this post I will dive into how to set up a reinforcement learning experiment using stable-baselines 3 which provides you an even quicker way to get started.
Read More ›
In my previous blog post on reinforcement learning I demonstrated a way to get a gentle introduction into this field by using Keras-RL2. While writing that I found it quite difficult to get an overview of the many reinforcement learning frameworks available today which all have different levels of maturity. In this post I will dive into how to set up a reinforcement learning experiment using stable-baselines 3 which provides you an even quicker way to get started.
Read More ›
I recently had written a Python program to perform some performance calculations over the results from a regression model. The program was not too complex but the sheer number of calculations to be performed made it quite slow and resulted in a runtime of several hours. In my search for a way to utilize the multiple cores of the machine the program was running on I came across the Ray package from https://www.ray.io/ which makes it very easy to distribute a single-core process onto multiple cores. Read More ›
In this post I will present a fast solution for loading CSV data into HANA by using Node.js. In the last year I have been working with Node.js as a generic command line programming tool I have noticed that as it has been optimized for fast I/O many problems are really faster when converted into JavaScript and run in Node.js. Read More ›